Loading post...
Please wait
June 4, 2025

Rust's approach to memory management is both powerful and nuanced. In this article, we’ll take a deep dive into how Rust handles memory at the level of its type system. Along the way, we’ll answer key questions such as:
libc play in all of this?A type that has no size at compile time. The entire size of this type is "collapsed" to zero during compilation.
Note: ZSTs always implement the Sized trait.
Example:
struct Marker;
Non-sized types (!Sized) whose length information isn’t encoded in the type itself. Their size is determined at runtime and stored as metadata associated with a pointer.
Examples:
str[T]dyn TraitDSTs must always be used behind pointers that carry additional metadata, such as:
&str&[T]Box<[T]>Rc<dyn Trait>The amount of data a CPU can process in one unit of time. The addressable memory space is determined by the machine word size of the CPU. For example, on a 64-bit processor, the word size is 64 bits (8 bytes).
Important Note:
In Rust, the size of a pointer (usize) is equal to the size of a machine word. This applies to fields like:
ptr (pointer to data)cap (capacity, e.g., in Vec)len (length, e.g., in String or slices)Once Rust code is compiled into an executable, the resulting binary file contains data, metadata, and machine instructions tailored for the target CPU architecture. This binary uses platform-specific formats such as:
Regardless of the specific format, the execution mechanism remains largely the same across platforms.
When a program (or process) is launched, the operating system kernel reads the segment metadata from the binary—such as .text (code), .data (initialized data), and .bss (uninitialized data)—and allocates the necessary memory based on this information.
This allocated memory forms the virtual address space of the process—a contiguous range of memory addresses that the process perceives as its own, from address 0 to the maximum available address.
📌 From the process’s perspective, it sees a flat, continuous block of memory—even though the actual physical RAM may be fragmented or only partially allocated.
Memory allocation is done lazily, meaning that although virtual memory is reserved upfront, the mapping to real physical memory occurs only when the memory is first accessed. This mapping is handled by a combination of:
At startup, the kernel maps the relevant segments (like .text, .data) into the process's virtual address space. The exact number and size of these segments depend on how the compiler structured the binary.

Below is an example of how memory sections are laid out in a compiled binary:
| Section | Size | Address |
|------------------|-------|---------------|
| `.vector_table` | 192 | `0x10000100` |
| `.text` | 33044 | `0x100001d4` |
| `.rodata` | 4904 | `0x100082e8` |
| `.data` | 0 | `0x20000000` |
| `.bss` | 4 | `0x20000000` |
| ... | | |
Each of these sections plays a specific role in the execution and memory layout of a Rust program. Let’s take a closer look at the most important ones.
.textThis section contains the compiled machine instructions (the executable code) of your program.
.dataThis section holds initialized global and static variables—that is, variables that have been assigned a value at compile time.
Example:
static MY_VAR: i32 = 42;
These values are stored directly in the binary and are loaded into memory when the program starts.
.bss (Block Started by Symbol)The .bss section stores uninitialized global and static variables.
.bss variables are initialized to zero before the main function runs.Example:
static mut UNINIT_VAR: i32 = 0; // Actually goes into .bss if uninitialized
⚠️ Note: In Rust, you typically avoid direct use of
.bssthrough safe code, but it's still used internally for certain kinds of static variables.
The stack is a region of memory located at the top of the user space and grows downward in memory (toward lower addresses).
use std::thread;
thread::Builder::new()
.stack_size(4 * 1024 * 1024) // 4MB stack size
.spawn(|| {
// thread logic here
});
Although the main thread is assigned an 8MB stack:
⚠️ This memory is not allocated all at once.
Instead, it follows a lazy allocation strategy — only the initially accessed pages are mapped into physical memory by the kernel.
This means that if your program doesn’t use the full stack, not all of the memory is actually used in RAM.
If a thread attempts to use more stack space than allowed:
💥 A stack overflow occurs, and the kernel terminates the thread (and often the whole program), usually with a segmentation fault or similar error.
The heap is a region of memory used for dynamic memory allocation and is shared among all threads in a process.
.text, .data, and .bss sections.This flexibility makes the heap ideal for allocating data whose size isn't known at compile time — such as Vec<T>, String, or boxed types like Box<T>.

The stack plays a crucial role in Rust’s execution model. Its primary purpose is to store data for the currently executing function — including:

Only variables with a fixed, known size at compile time can be placed directly on the stack.
This includes:
i32, bool, char[u8; 16]Types with dynamic or unknown size (like str, [T], or trait objects) must be accessed via pointers (e.g., &str, Box<[T]>).
A stack frame is the block of memory allocated for the execution of a single function. It contains:
The stack pointer is a CPU register that keeps track of the current top of the stack.
✅ Because this is just a simple pointer adjustment, allocation and deallocation on the stack are extremely fast — no system calls are needed.
Let’s walk through how stack frames are created during function calls:
A stack frame is first created for the main() function.
main() calls another function, say add_one().
add_one(), large enough to hold its local data.The return address, e.g., 0x23f, points to the next instruction in main() — typically the line after the function call (e.g., let b = add_one(a);).
add_one() finishes.After add_one() returns:
main()).add_one()'s stack frame isn’t immediately cleared — it will simply be overwritten when the next function is called.📌 This lazy cleanup is part of what makes stack operations so efficient.
In Rust, heap memory allocation is managed through the GlobalAlloc trait — a core abstraction that defines the functions an allocator must implement.
By default, Rust uses the malloc function from the standard C library (libc) to manage dynamic memory. This means:
⚠️ Rust assumes the presence of
libcon the target platform for standard heap allocations.
Allocating and managing memory on the heap is generally slower than stack operations, mainly due to:
libc for requesting or releasing memory.To minimize performance overhead and reduce the number of system calls, modern allocators often:
🔄 Request memory in larger blocks and manage them internally, reusing chunks as needed.
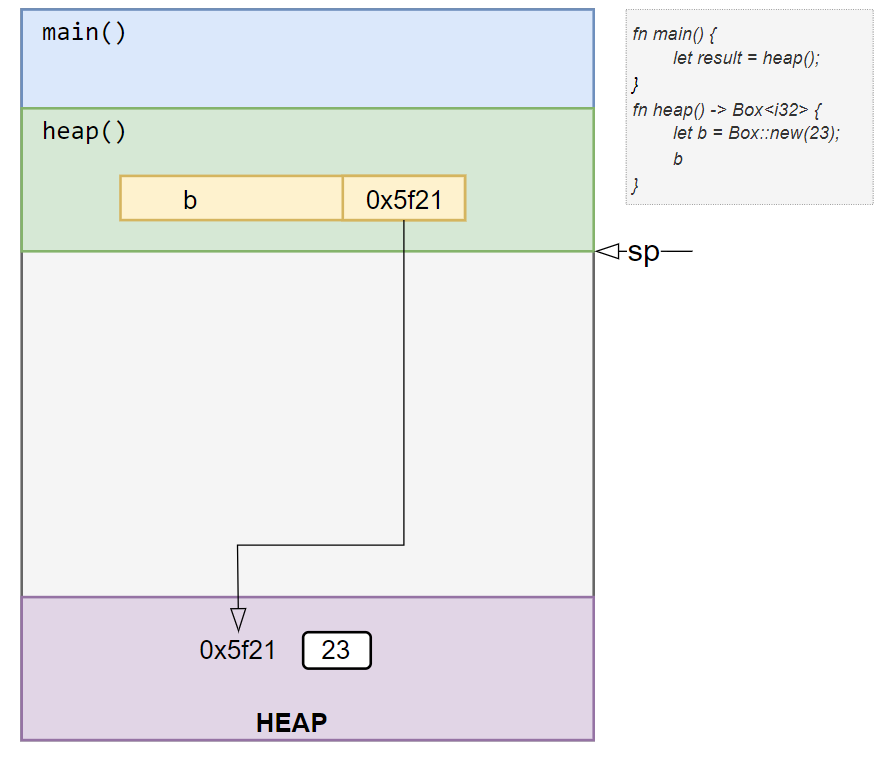
Let’s walk through a simple example using Box<T>:
main() function.heap().Inside heap():
Box<i32> is created with the value 23.i32 takes 4 bytes, space for it is allocated on the heap.0x5f21) is stored in the variable b on the stack.usize, which is 8 bytes on 64-bit systems), b can safely live on the stack.When heap() returns:
main() via the return address (e.g., 0x5f21).heap() is deallocated, the data on the heap remains intact.result variable in main() now holds the pointer to that heap-allocated data.✅ This is what makes heap-allocated data long-lived — it persists beyond the scope of the function that created it, until explicitly dropped or goes out of scope in Rust.
In Rust, integer types are fundamental data types that are stored entirely on the stack, making them fast and efficient to work with.
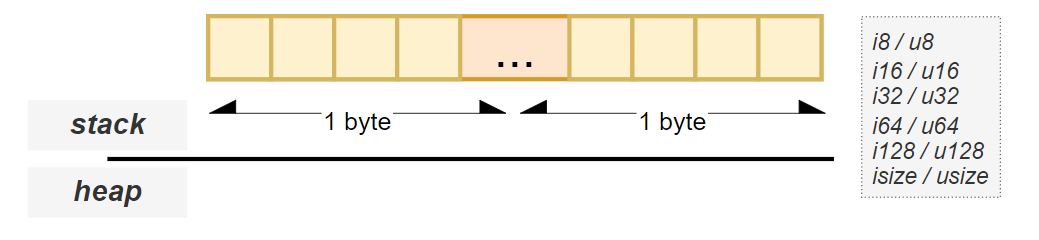
Rust supports both signed and unsigned integers:
i): Can represent both positive and negative numbers.u): Only non-negative numbers (0 and positive).Each type indicates how many bits it uses in memory.
| Type | Size | Description |
|--------------|-----------|-------------------------------------|
| `i8` / `u8` | 1 byte | 8-bit signed/unsigned integer |
| `i16` / `u16`| 2 bytes | 16-bit signed/unsigned integer |
| `i32` / `u32`| 4 bytes | 32-bit signed/unsigned integer |
| `i64` / `u64`| 8 bytes | 64-bit signed/unsigned integer |
| `i128` / `u128` | 16 bytes | 128-bit signed/unsigned integer |
Although not integers, floating-point types are also stack-allocated and included here for completeness:
| Type | Size | Description |
|----------|-------------|---------------------------|
| `f32` | 4 bytes | 32-bit IEEE 754 float |
| `f64` | 8 bytes | 64-bit IEEE 754 float |
These types vary in size depending on the target architecture:
| Type | Size on 32-bit | Size on 64-bit | Use Case |
|--------------|----------------|----------------|---------------------------------|
| `isize` | 4 bytes | 8 bytes | Signed index/size values |
| `usize` | 4 bytes | 8 bytes | Unsigned index/size values |
📌 These types are especially useful when working with memory addresses or collections like
Vec<T>where indexing and length tracking are needed.
The char type in Rust is a primitive data type that represents a single Unicode Scalar Value.
i32, u8, and bool, it is stored on the stack by default.a, Z, 0, etc.)€, ©, ®)🦀, 🔥, 🌍)Regardless of the complexity or visual representation of the character, every char in Rust uses exactly 4 bytes of memory.
This ensures consistent and efficient handling of text at the lowest level, making operations like indexing and storage predictable and fast.
📌 Example:
'a','€', and'🦀'all occupy 4 bytes in memory when stored as achar.
A tuple is a composite type that consists of a fixed set of values, potentially of different types.
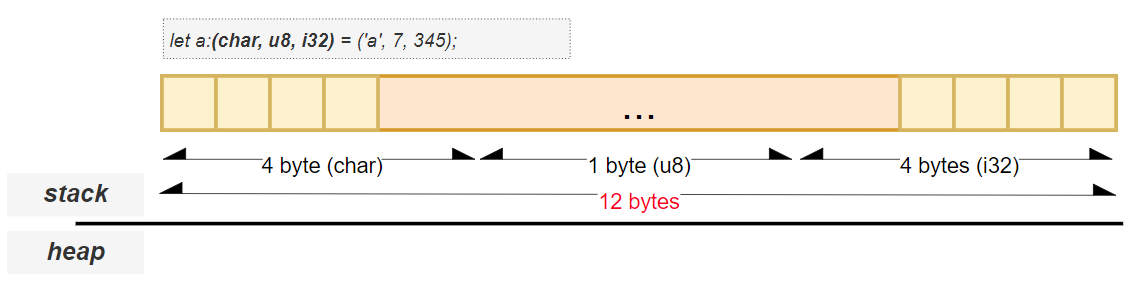
Rust (and most systems) align data in memory to allow the CPU to read it more efficiently. This means:
📏 The compiler inserts padding bytes between fields so that each field starts at a memory address that is a multiple of its alignment requirement.
Consider the tuple (char, u8, i32):
| Type | Size (bytes) |
|---------|--------------|
| `char` | 4 |
| `u8` | 1 |
| `i32` | 4 |
Sum of sizes:
4 + 1 + 4 = 9 bytes
But due to alignment rules:
char (4 bytes), u8 takes 1 byte, followed by 3 padding bytes to align the next field (i32) to a 4-byte boundary.Let’s break down how the aligned size is calculated:
9 / 4 = 2.25 → round up to 34 * 3 = 12 bytesstd::mem::size_of::<(char, u8, i32)>(); // returns 12
std::mem::align_of::<(char, u8, i32)>(); // returns 4
This ensures that each field is properly aligned in memory, improving performance and preventing hardware faults on some architectures.
In Rust, references allow you to refer to a value without taking ownership of it. They are a core feature of the language and are stored on the stack by default.
&T – Shared Reference&T) contains the memory address of the original variable it points to.let x = 42;
let r = &x; // r is a shared reference to x
📌 Size of
&Tis equal tousize— typically 8 bytes on 64-bit systems.
&&T – Reference to a Reference&&T) is still just a pointer to another pointer.let x = 42;
let r1 = &x;
let r2 = &r1; // r2 is a reference to a reference
&mut T – Mutable Reference&mut T) has the exact same memory layout as a shared reference (&T).&T and &mut T lies in semantics and borrow checking, not in how they are represented in memory.let mut x = 42;
let m = &mut x; // m is a unique mutable reference to x
⚠️ While the layout is the same, Rust enforces strict rules at compile time:
- Only one mutable reference can exist to a piece of data in a particular scope.
- No other references (mutable or shared) can coexist with an active mutable reference.
In Rust, an array is a fixed-size collection of elements, all of the same type.
let a: [i32; 3] = [55, 66, 77];
[i32; 3] and [i32; 4] are considered different types.This makes arrays very efficient for use cases where the number of elements is known ahead of time and doesn’t need to grow or shrink.
📌 Because arrays have a fixed layout and known size, they are ideal for low-level systems programming and performance-sensitive code.
In Rust, Vec<T> is a growable, heap-allocated list type that provides a dynamic alternative to fixed-size arrays.
let v: Vec<i32> = vec![55, 66, 77];
T.A Vec<T> stores three values on the stack:
| Field | Description |
|-------|-------------|
| `ptr` | A pointer to the start of the allocated memory block on the heap. |
| `len` | The number of elements currently in the vector. |
| `cap` | The total number of elements the vector can hold before needing to reallocate. |
This makes Vec<T> a fat pointer — it contains more than just an address.
When the length (len) reaches the capacity (cap) and you try to add another element:
⚠️ Reallocation is relatively expensive, so it’s often optimized by increasing capacity exponentially (e.g., doubling it), reducing how often it happens.
In Rust, a slice ([T]) is a view into a contiguous sequence of elements in memory. It is similar to a fixed-size array, but with one key difference:
🔄 The size doesn’t need to be known at compile time and is instead determined at runtime.
let a: [i32; 3] = [55, 66, 77];
let v: Vec<i32> = vec![55, 66, 77];
let s1: &[i32] = &a[0..2]; // slice of the array
let s2: &[i32] = &v[0..2]; // slice of the vector
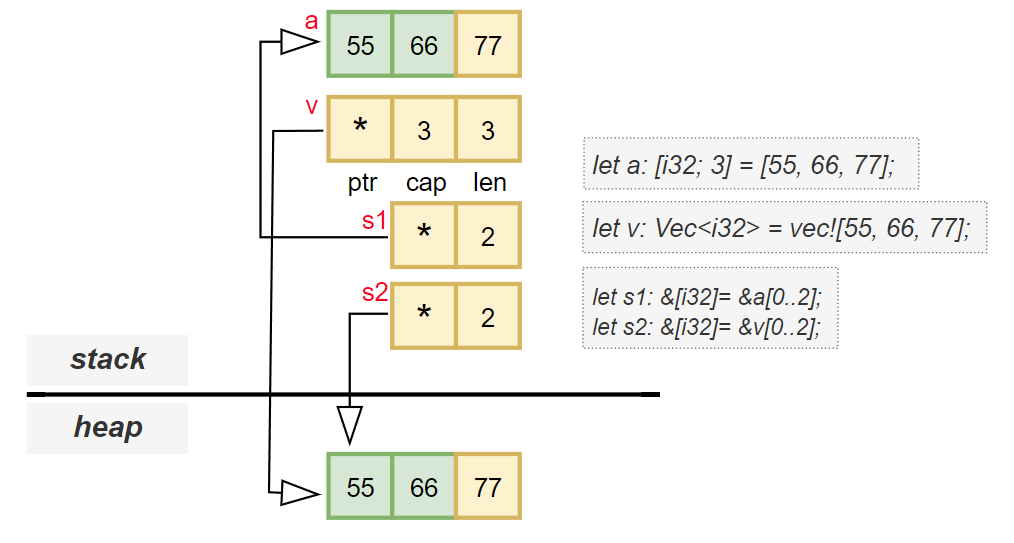
These slices give you a way to refer to a portion of the data without taking ownership.
Slices themselves are not directly usable — they must be accessed through a reference, such as &[T]. This reference is what’s called a fat pointer, which contains two pieces of information:
| Part | Description |
|--------|-------------|
| `ptr` | A pointer to the first element in the slice (`*const T`) |
| `len` | The number of elements in the slice (`usize`) |
This means that while the type [T] itself does not carry length information, the reference to it (&[T]) does.
✅ So even though
[T]is a dynamically sized type (DST), using it behind a reference like&[T]makes it usable by attaching metadata (length) to the pointer.
String, str, and &strIn Rust, strings are a core part of the language but come in different forms, each with its own purpose and memory behavior.
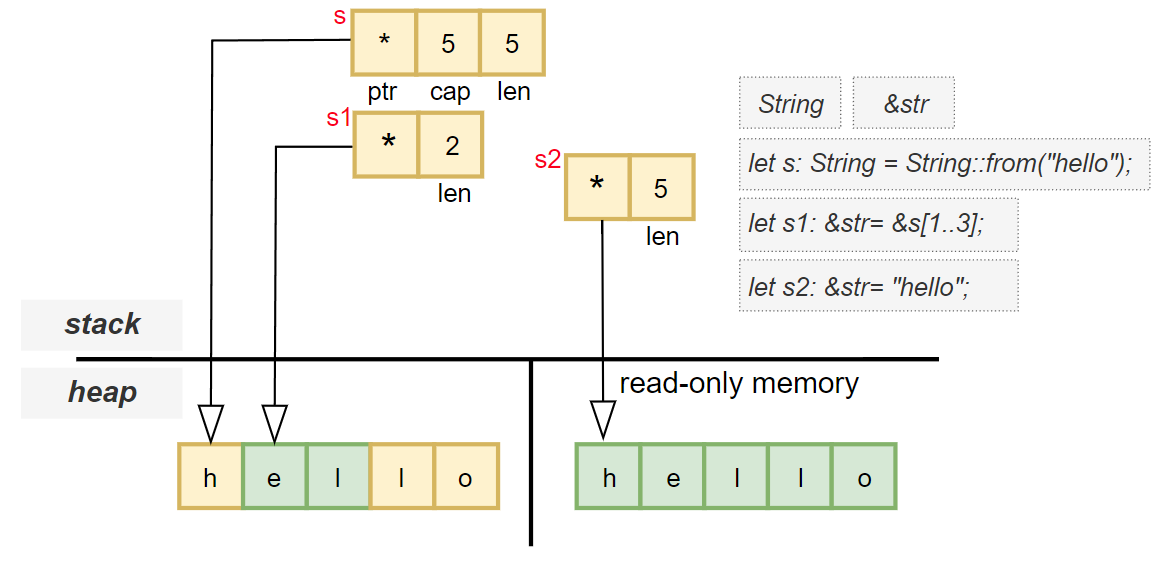
String – A Heap-Allocated String TypeA String is essentially a heap-allocated wrapper around a Vec<u8>, with additional guarantees that the bytes represent valid UTF-8 text.
Like a vector, a String stores three values on the stack:
| Field | Description |
|-------|-------------|
| `ptr` | Pointer to the start of the UTF-8 encoded string data on the heap |
| `len` | Length of the current string (in bytes) |
| `cap` | Total allocated capacity in bytes |
This makes String a flexible, growable container for text.
let s: String = String::from("hello");
This allocates "hello" on the heap and manages it via the String type on the stack.
&'static str – String LiteralsWhen you assign a string literal directly to a variable:
let s2: &'static str = "hello";
The type of s2 is a string slice (&str) with a 'static lifetime. These literals are:
.rodata section of the binary (read-only data)The variable s2 is represented as a fat pointer, containing:
| Part | Description |
|------|-------------|
| `ptr` | Pointer to the location of `"hello"` in read-only memory |
| `len` | Length of the string (5 bytes in this case) |
You can get the raw pointer like this:
let ptr: *const u8 = s2.as_ptr();
🔒 Because these strings live in read-only memory, they are immutable and have a static lifetime.
str – The Primitive String TypeThe str type in Rust is a dynamically sized type (DST). It represents a sequence of UTF-8 bytes but does not include length information in the type itself.
⚠️ You cannot declare a variable of type
strdirectly — because its size isn’t known at compile time.
Instead, you always use it behind a reference:
&str // This is the common form
Which gives you a fat pointer made up of:
*const u8)usize)This makes &str safe to store on the stack and efficient to pass around.
Just like with arrays and vectors, you can create slices from a String:
let s1: &str = &s[1..3];
This returns a new slice referencing a portion of the original string.
📌 Important Notes:
- No data is copied — only a reference is created.
- The slice includes metadata about the length.
- Since
strhas no known size, you must use a reference when slicing.
Understanding the difference between String and &str is crucial for writing efficient and idiomatic Rust code.
In Rust, structs are custom data types that let you group together named values (or unnamed in some cases) to create meaningful abstractions.

| Type | Description |
|-------------------|-------------|
| **Named-field struct** | Classic structs with fields that have both a name and a type. |
| **Tuple struct** | Structs without field names — behave like tuples with a custom type identity. |
| **Unit-like struct** | A struct with no fields — behaves like a **ZST (Zero-Sized Type)**. |
📌 Unit-like structs are often used for marker types or implementing traits without carrying any data.
A struct with named fields stores all its data inline, typically on the stack, assuming all of its fields can be placed there.
For example:
struct User {
name: String,
age: u32,
}
This struct contains:
String — which itself is a stack-allocated pointer + length + capacity, pointing to heap data.u32 — a simple primitive stored directly on the stack.These fields are laid out next to each other in memory, just like a tuple.
✅ So internally, a struct with named fields has a layout similar to a tuple struct — just with named accessors.
If a struct contains a type that uses heap memory (like Vec<T> or String), then:
Example:
struct Data {
nums: Vec<i32>,
}
nums is a Vec<i32>, so:
ptr, len, cap) lives on the stack inside Data🔄 This means structs themselves can be stack-only or indirectly reference heap data, depending on their contents.
Enums in Rust are a powerful way to represent data that can be one of several possible variants. They come in different forms and have nuanced memory layouts depending on their usage.
A basic enum with unit-like variants is stored internally as an integer, with each variant assigned a numeric tag starting from 0.
enum HTTPStatuses {
OK,
NotFound,
}
📌 In this case, only two variants exist (
0and1), so the enum can be represented using just 1 byte (u8).
You can also assign explicit integer values to enum variants:
enum HTTPStatuses {
OK = 200,
NotFound = 404,
}
In this case:
404, which requires at least 2 bytes (u16) to store.🧠 This ensures uniform size across all variants — a key requirement for safe and predictable memory layout.
Rust enums can also carry data, making them even more expressive.
enum Data {
Empty,
Number(i32),
Array(Vec<i32>),
}
Each variant may have a different internal structure, but:
✅ All variants must occupy the same amount of memory.
To achieve this, Rust uses the following strategy:
Vec<i32>).0, 1, 2) to identify which variant is currently active.This makes enums with payloads both safe and efficient, while still allowing complex data to be stored inline when possible.
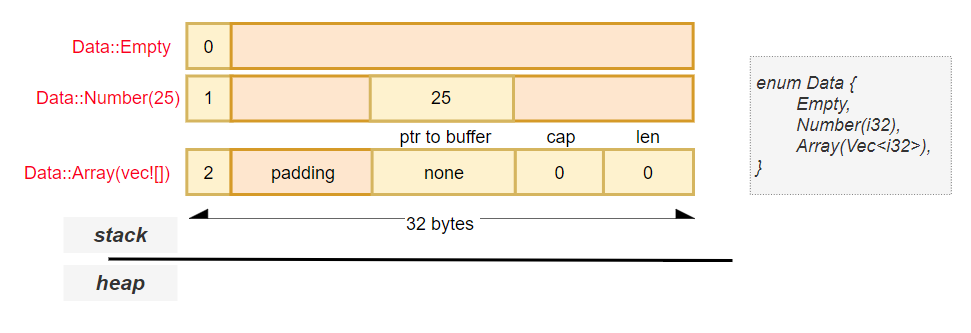
BoxIn Rust, enums can become quite large in memory when they contain heavy variants — especially those that store heap-allocated types like Vec<T>.
One effective way to optimize the size of an enum is by wrapping large variants in a Box<T>, which stores the data on the heap and only keeps a pointer on the stack.
Boxenum Data {
Empty,
Number(i32),
Array(Vec<i32>),
}
In this case:
Vec<i32> (which includes ptr, len, and cap) must be stored inline within the enum.Empty or Number.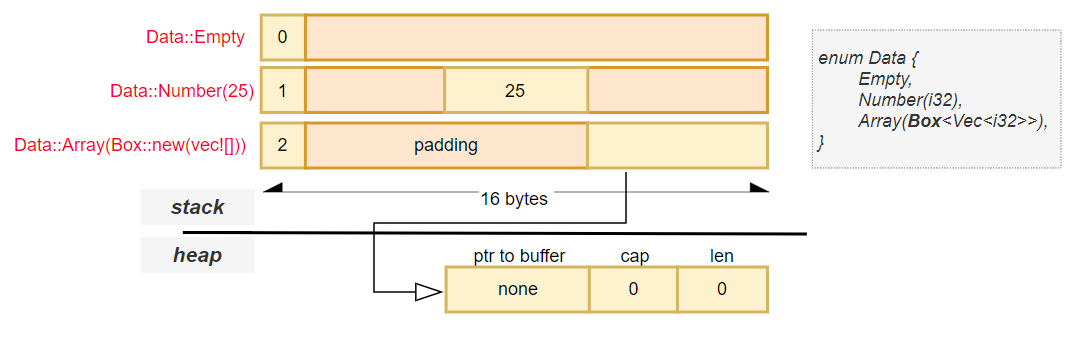
BoxTo reduce the overall size of the enum, we can box the vector:
enum Data {
Empty,
Number(i32),
Array(Box<Vec<i32>>),
}
Now:
Vec<i32>, the Array variant stores just a pointer (*const Vec<i32>) — which is a single machine word.Let’s break down what happens under the hood:
Array, a pointer (ptr) to where the boxed Vec<i32> is stored in heap memoryVec<i32>
ptr), length (len), and capacity (cap)i32 values stored in the vectorThis creates a chain of indirection:
Stack → ptr → Heap (Box) → ptr → Heap (Vec) → ptr → Heap (data)
⚠️ While this adds a level of indirection, it significantly improves memory efficiency for large variants — making it a great trade-off in many cases.
Rust’s ownership system governs how data is copied or moved between variables. The behavior depends on whether the type is stored entirely on the stack (simple types) or involves heap allocation.
For primitive types like i32, bool, char, and small fixed-size arrays:
let a = 42;
let b = a; // `a` is copied into `b`
✅ These types implement the
Copytrait, meaning they are duplicated automatically on assignment or function calls.
For types that involve heap allocation, such as Vec<T> or String, copying isn't automatic — for good reason.
Let’s take an example:
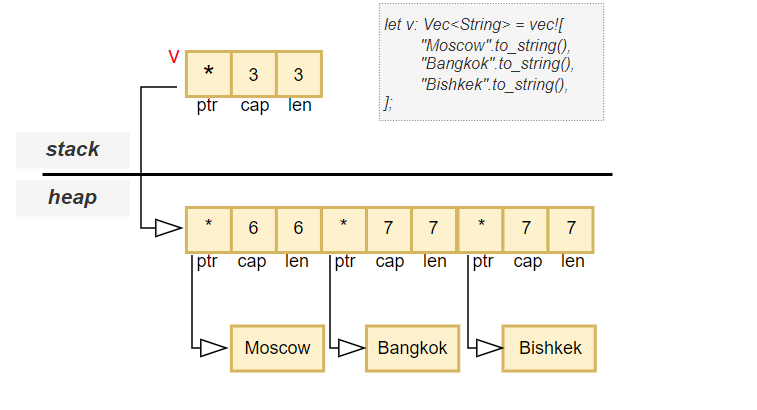
let v = vec![String::from("hello"), String::from("world")];
Each String inside the vector has this internal structure:
ptr) to the actual UTF-8 bytes on the heaplen)cap)These three values (each of type usize) make up the string header, and are stored inline within the vector.
The vector itself also contains:
So, on the stack, you get:
usize) representing the vector headerOn the heap, you get:
When you assign a heap-allocated value to a new variable:
let v2 = v;
This results in a move, not a copy.
v) is invalidated — it no longer owns the data.v2) becomes the sole owner of the heap-allocated memory.v to v2.⚠️ No deep copy of the heap data occurs — both variables point to the same memory region.
At the end of the scope, when v2 goes out of scope, its drop() function is called, freeing the memory once and for all.
If you want two independent copies of the same data, you must explicitly request a deep copy using .clone():
let v2 = v.clone();
Now:
📌 This ensures safety and clarity — if you want a full copy, you have to ask for it.
Rc<T>In Rust, the ownership model ensures memory safety by enforcing strict rules about who owns and can modify data. But what if you want a value to have multiple owners?
That’s where Rc<T> — short for Reference Counted — comes in.
Rc<T>You use Rc<T> when:
Unlike regular references (which are temporary), Rc<T> allows multiple strong references to the same data, and keeps the data alive as long as at least one reference exists.
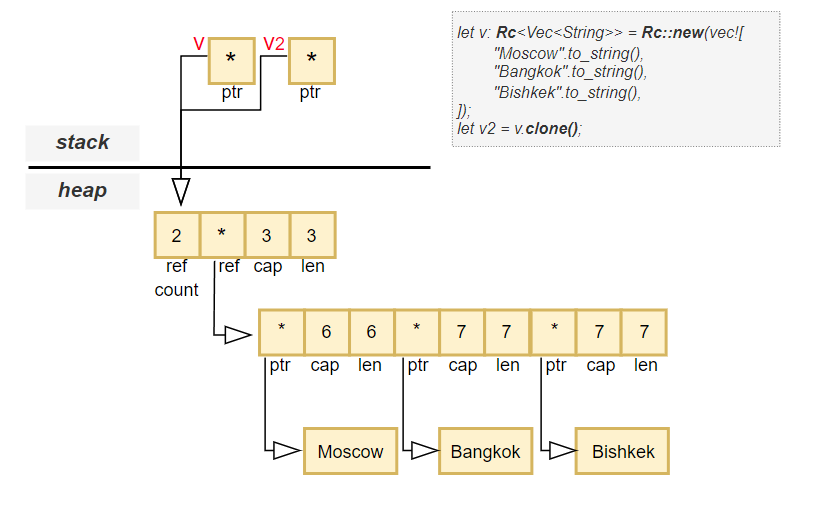
Rc<T> WorksLet’s look at an example:
use std::rc::Rc;
let v: Rc<Vec<String>> = Rc::new(vec![
"Odin".to_string(),
"Thor".to_string(),
"Loki".to_string(),
]);
let v2 = v.clone();
Under the hood:
ptr, len, cap), Rc<T> also allocates space for a reference count..clone() on an Rc<T>, this counter is incremented.Rc<T> variable goes out of scope, the counter is decremented.Each Rc<T> variable (like v and v2) stores just one thing:
usize) pointing to the shared data on the heap.The actual allocation contains:
Vec<String>)This makes Rc<T> very efficient in terms of stack usage, while still managing complex heap allocations safely.
One important restriction:
🔒 Values inside an
Rc<T>are immutable by default.
If you try to mutate the inner value, you’ll get a compile-time error unless you use interior mutability patterns like RefCell or Mutex.
Send and SyncIn Rust, concurrency is handled with strong compile-time guarantees to prevent data races. Two important traits that enable this are:
SendSyncThese traits are used by the compiler to determine whether a type can be safely shared or transferred between threads.
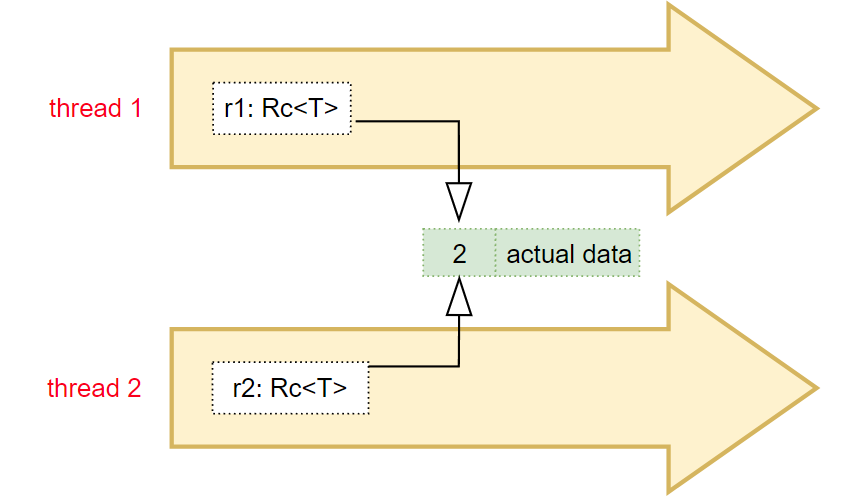
Send – Safe to Transfer Ownership Across ThreadsA type that implements Send indicates that:
✅ It is safe to move its value from one thread to another.
More precisely:
T: Send means ownership of T can be transferred across thread boundaries.thread::spawn.Example:
use std::thread;
let data = vec![1, 2, 3];
thread::spawn(move || {
println!("{:?}", data);
}).join().unwrap();
This compiles only because Vec<T> (and thus data) implements Send.
Sync – Safe to Share References Across ThreadsA type that implements Sync indicates that:
✅ It is safe to share immutable references (
&T) between threads.
In other words:
T: Sync means it’s safe for multiple threads to have access to the same &T.Example:
use std::sync::Arc;
use std::thread;
let data = Arc::new(vec![1, 2, 3]);
let data_clone = Arc::clone(&data);
thread::spawn(move || {
println!("From thread: {:?}", data_clone);
}).join().unwrap();
This works because Arc<Vec<i32>> is both Send and Sync.
Send and Sync| Trait | Meaning | Implies |
|-------|---------|---------|
| `Send` | Safe to transfer ownership to another thread | `T` can be moved between threads |
| `Sync` | Safe to share immutable references between threads | `&T` can be sent between threads |
Also:
T is Sync, then &T is Send.i32, bool, and pointers like &'static str are both Send and Sync.Rc Is Not Send or SyncThe Rc<T> type is not thread-safe, and therefore does not implement Send or Sync.
Why?
Because:
Rc<T> maintains a reference count in shared memory.Rc<T> pointing to the same value and try to clone or drop at the same time, this can lead to a data race on the reference count.Example:
use std::rc::Rc;
use std::thread;
let counter = Rc::new(0);
let counter_clone = Rc::clone(&counter);
thread::spawn(move || {
// ❌ Compile error! `Rc` is not `Send`
let _ = counter_clone;
}).join().unwrap();
To safely share reference-counted values between threads, use Arc<T> instead — the Atomic Reference Counted pointer, which is thread-safe and implements both Send and Sync.
Primitive types (i32, bool, etc.):
Send: YesSync: YesVec<T>, String:
Send: YesSync: Yes&T (if T: Sync):
Send: YesSync: Not applicable (references themselves are not Sync)Rc<T>:
Send: NoSync: NoArc<T>:
Send: YesSync: YesRefCell<T> / Cell<T>:
Send: NoSync: NoMutex<T>:
Send: Yes (if T: Send)Sync: Yes (if T: Sync)Arc<T>When you need to share data between threads, Rust provides a thread-safe version of Rc<T> called Arc<T> — short for Atomic Reference Counted.
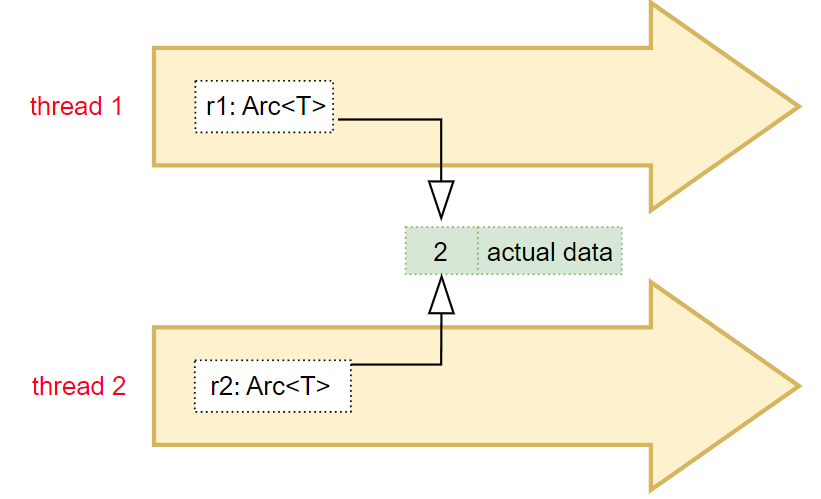
Arc<T>Use Arc<T> when:
It works similarly to Rc<T>, but with one crucial difference:
🔐 The reference count is modified using atomic operations, making it safe to use across threads.
Arc<T> WorksLike Rc<T>, each time you call .clone() on an Arc<T>:
This ensures that even in a multi-threaded context, memory is managed correctly and safely.
Because atomic operations are involved:
⚠️
Arc<T>has a small performance cost compared toRc<T>.
This overhead comes from ensuring thread safety during reference counting. However, in most cases, this cost is negligible compared to the benefits of safe concurrency.
Just like Rc<T>, values inside an Arc<T> are immutable by default.
Even though multiple threads may hold a reference to the same data:
🚫 They cannot modify the value unless combined with interior mutability types like
Mutex<T>orRwLock<T>.
Example:
use std::sync::{Arc, Mutex};
use std::thread;
let data = Arc::new(Mutex::new(0));
let data_clone = Arc::clone(&data);
thread::spawn(move || {
let mut num = data_clone.lock().unwrap();
*num += 1;
}).join().unwrap();
println!("Data: {}", *data.lock().unwrap()); // Output: Data: 1
In this example:
Arc enables shared ownership across threads.Mutex ensures safe, exclusive access to the inner value for mutation.