Loading post...
Please wait
January 2, 2024
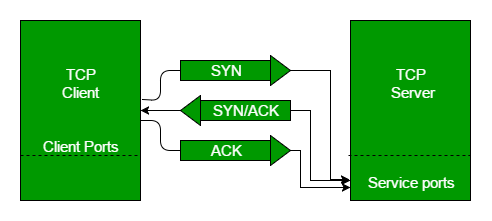 Figure 1: TCP connection establishment and state transitions
Figure 1: TCP connection establishment and state transitions
Accessing a webpage or interacting with a web application may seem simple, but it triggers a complex journey through multiple system layers. From the moment a client initiates a connection to the server's final response, data traverses multiple layers of abstraction, each playing a crucial role in ensuring a seamless and tailored user experience. Let's delve into the ten key stages of this process, with a particular focus on how memory layout considerations impact efficiency at each step.
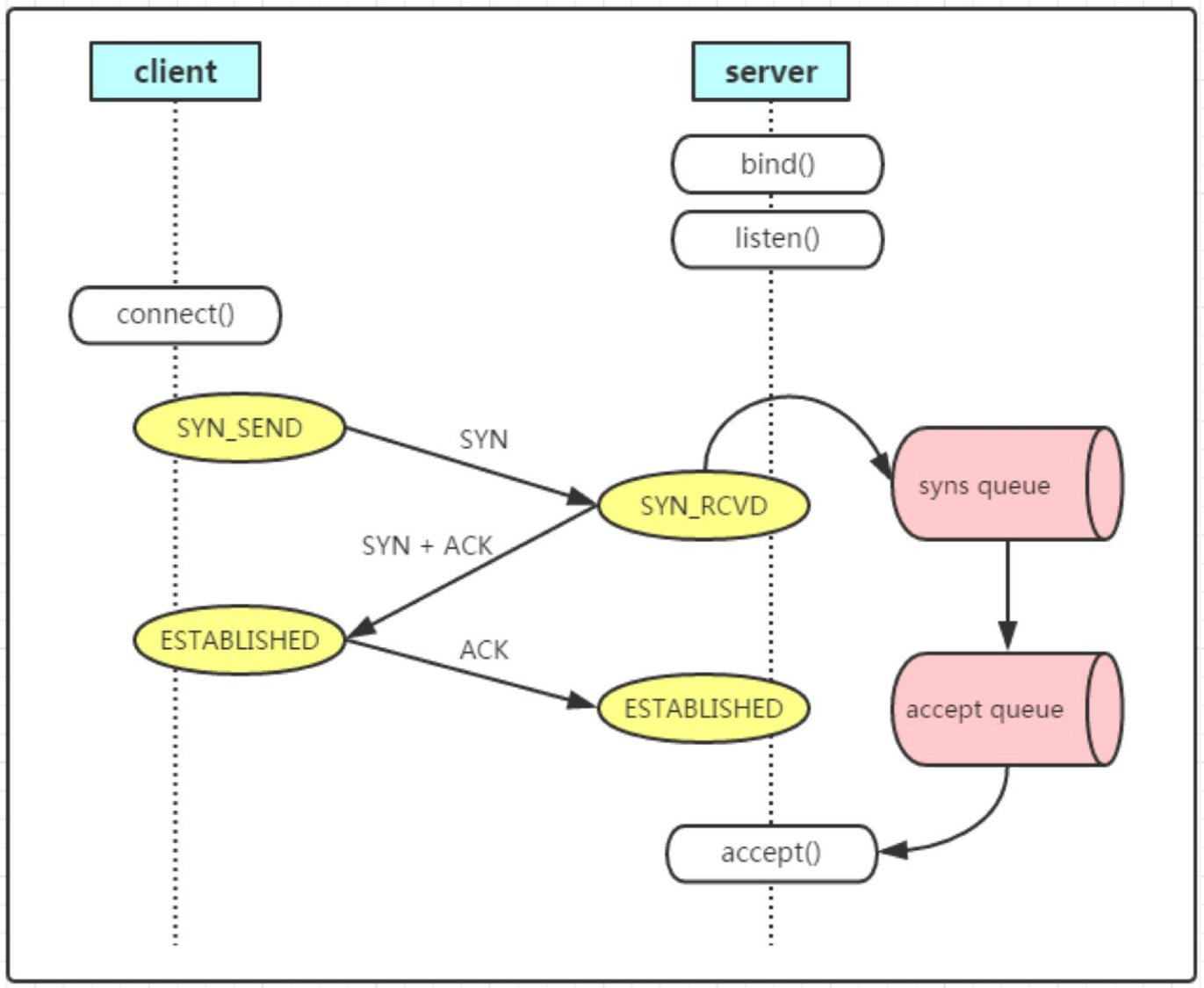 Figure 2: File descriptor table and kernel memory
Figure 2: File descriptor table and kernel memory
The client initiates a connection by sending a SYN packet to the server's operating system (OS) kernel. If the server is listening on the specified port, the kernel responds with a SYN-ACK, and the client completes the handshake with an ACK, establishing a TCP or QUIC connection. The kernel then places this newly established connection in a dedicated accept queue, a region of kernel memory designed to hold pending connections. When the backend application is ready to handle a new request, it calls the accept() system call (syscall). This syscall retrieves a file descriptor, a small integer that acts as an index into a kernel-managed table (often a file descriptor table within the process's memory space), representing the established connection. This file descriptor provides a handle for subsequent read and write operations.
Memory Layout Insight: The accept queue is a finite-size buffer in kernel memory. Its size is a critical tuning parameter. A small queue can lead to dropped connections under heavy load, as the kernel cannot hold all incoming connection requests. Conversely, an excessively large queue might consume unnecessary kernel memory. The file descriptor itself is a small piece of data in the application's memory space, but it points to a more substantial data structure within the kernel that maintains the connection's state (e.g., socket buffers, peer address).
 Figure 3: User space and kernel space memory separation
Figure 3: User space and kernel space memory separation
Once the connection is established, the client sends the HTTP request as a stream of bytes. The server's Network Interface Card (NIC) receives these bytes and, using Direct Memory Access (DMA—a technique that allows hardware to transfer data directly to memory without CPU intervention), places them into the OS kernel's receive buffer for the connection. The backend application then invokes the read() or recv() syscall, which triggers the kernel to copy the request bytes from the kernel's receive buffer into the user space memory buffer allocated by the application.
Memory Layout Insight: The size of the kernel's receive buffer significantly impacts network performance. A larger buffer can accommodate bursts of data and reduce packet loss due to buffer overflows. However, excessively large buffers can consume significant kernel memory per connection. The
read()/recv()syscall involves a memory copy operation between kernel space and user space. Optimizing the size and number of these copies is crucial for performance. Techniques like zero-copy—where data moves directly between the network interface and the application's buffer, bypassing intermediate kernel copies—can greatly improve efficiency for high-throughput applications. However, these optimizations often require specialized APIs and hardware support.
For secure HTTPS connections, the received bytes are encrypted using Transport Layer Security (TLS). The backend application utilizes an SSL/TLS library (e.g., OpenSSL) to decrypt these bytes. This involves cryptographic operations performed in the application's user space memory. The encrypted data is read from the application's buffer, and the decrypted data is written to another buffer in user space.
Memory Layout Insight: The SSL/TLS library manages its own memory for cryptographic keys, session data, and intermediate buffers during the decryption process. The efficiency of the decryption depends on the algorithms used and the library's implementation, including how it manages memory allocations and deallocations. Optimizations often involve minimizing memory copies and using efficient data structures for cryptographic operations.
The backend application employs an HTTP parsing library to analyze the decrypted request bytes. This library examines the byte stream to identify the request method, resource path, headers, and potentially the message body. The parsed information is typically stored in data structures (e.g., dictionaries, objects) within the application's user space memory.
Memory Layout Insight: The efficiency of the parsing process depends on how the parsing library manages memory for the input byte stream and the resulting parsed data structures. Well-optimized parsers minimize unnecessary memory allocations and copies, often using techniques like in-place parsing or efficient string manipulation.
If the request body contains structured data encoded in formats like JSON or Protocol Buffers, the backend application uses a decoding library to convert this data into native language objects (e.g., Python dictionaries or custom class instances). This involves reading the encoded data from a memory buffer and creating corresponding in-memory representations.
Memory Layout Insight: The choice of data format and decoding library significantly impacts memory usage and performance. Binary formats like Protocol Buffers are generally more memory-efficient and faster to decode than text-based formats like JSON. Decoding libraries need to efficiently allocate memory for the resulting objects and manage the parsing process to minimize overhead.
This is the core logic of the backend application. Based on the parsed and decoded request, the application performs various operations, such as querying databases, performing calculations, or executing business rules. This stage heavily involves manipulating data within the application's user space memory.
Memory Layout Insight: The memory layout of the application's data structures, algorithms, and caching mechanisms directly impacts the performance of this stage. Efficient data structures (e.g., hash maps, balanced trees) allow for fast data access and manipulation. Caching frequently accessed data in memory can significantly reduce the need for expensive operations like database queries. Memory management practices, such as avoiding excessive object creation and destruction, are also crucial for preventing performance degradation due to garbage collection.
Once the request is processed, the backend application constructs an HTTP response. This includes setting the status code, adding relevant headers, and creating the response body (e.g., HTML content, JSON data, images). The response data is typically built in user space memory buffers.
Memory Layout Insight: The way the response is constructed in memory can affect performance. For example, efficiently concatenating strings or building complex data structures for the response body is important. For large responses, techniques like streaming can be used to avoid loading the entire response into memory at once.
If the connection is secured with TLS, the backend application uses the SSL/TLS library to encrypt the response data residing in its user space memory. The encrypted data is then stored in another memory buffer, ready for transmission.
Memory Layout Insight: Similar to decryption, the efficiency of encryption depends on the algorithms and the SSL/TLS library's memory management. Optimizations aim to minimize memory copies and efficiently handle cryptographic operations.
The encrypted (or unencrypted) response bytes are then sent back to the client. The application uses the write() or send() syscall to transfer the response data from its user space memory to the kernel's send buffer associated with the connection. The OS kernel then handles the transmission of these bytes to the client's NIC. DMA may again be used to transfer data from the kernel's send buffer to the NIC.
Memory Layout Insight: The size of the kernel's send buffer influences the rate at which data can be sent. A larger buffer can accommodate temporary bursts of outgoing data. The
write()/send()syscall involves a memory copy from user space to kernel space. Similar to the receive path, zero-copy techniques can be employed for high-performance scenarios to reduce this overhead.
After the response is sent, the backend application can decide to close the connection using the close() syscall or keep it alive (e.g., for HTTP keep-alive) to handle subsequent requests from the same client. Closing the connection involves releasing the kernel resources associated with the file descriptor and the connection state.
Memory Layout Insight: Closing the connection frees up the kernel memory associated with the connection (e.g., socket buffers, connection state). Keeping connections alive can reduce the overhead of establishing new connections for subsequent requests but requires managing the state of these idle connections in kernel memory.
Understanding the memory layout at each stage of HTTP request processing is essential for building high-performance, scalable backend systems. By optimizing buffer sizes, minimizing unnecessary memory copies, and choosing efficient data structures, engineers can significantly improve throughput and resource utilization. Memory-level optimizations, from kernel buffers to application-level caching, are foundational for modern web application performance.