Loading post...
Please wait
January 31, 2024
Web applications demand responsiveness, but not all workloads fit neatly into the classic request-response model. When requests involve extended processing times or when we want the server to trigger updates asynchronously, short polling offers us a pragmatic and widely applicable solution. Although it looks simple on the surface, using short polling effectively requires us to understand memory usage, kernel involvement, and the right trade-offs between efficiency and responsiveness.

In a typical HTTP request-response cycle, the client sends a request and then waits until the server computes and responds. This model works beautifully for instant results. But consider uploading a large video, compiling code, or running a complex simulation: these operations take time. Holding an HTTP connection open wastes server memory, and threads could be tied up unnecessarily.
An analogy helps here. Imagine waiting at a doctor’s office: instead of standing at the counter constantly asking "is my appointment ready?", you check in, then return at reasonable intervals. Short polling follows this efficient check-in model—it reduces wasted effort while keeping progress visible to the client.
The short polling cycle can be broken into well-defined steps, forming a structured communication dance between the client and server:
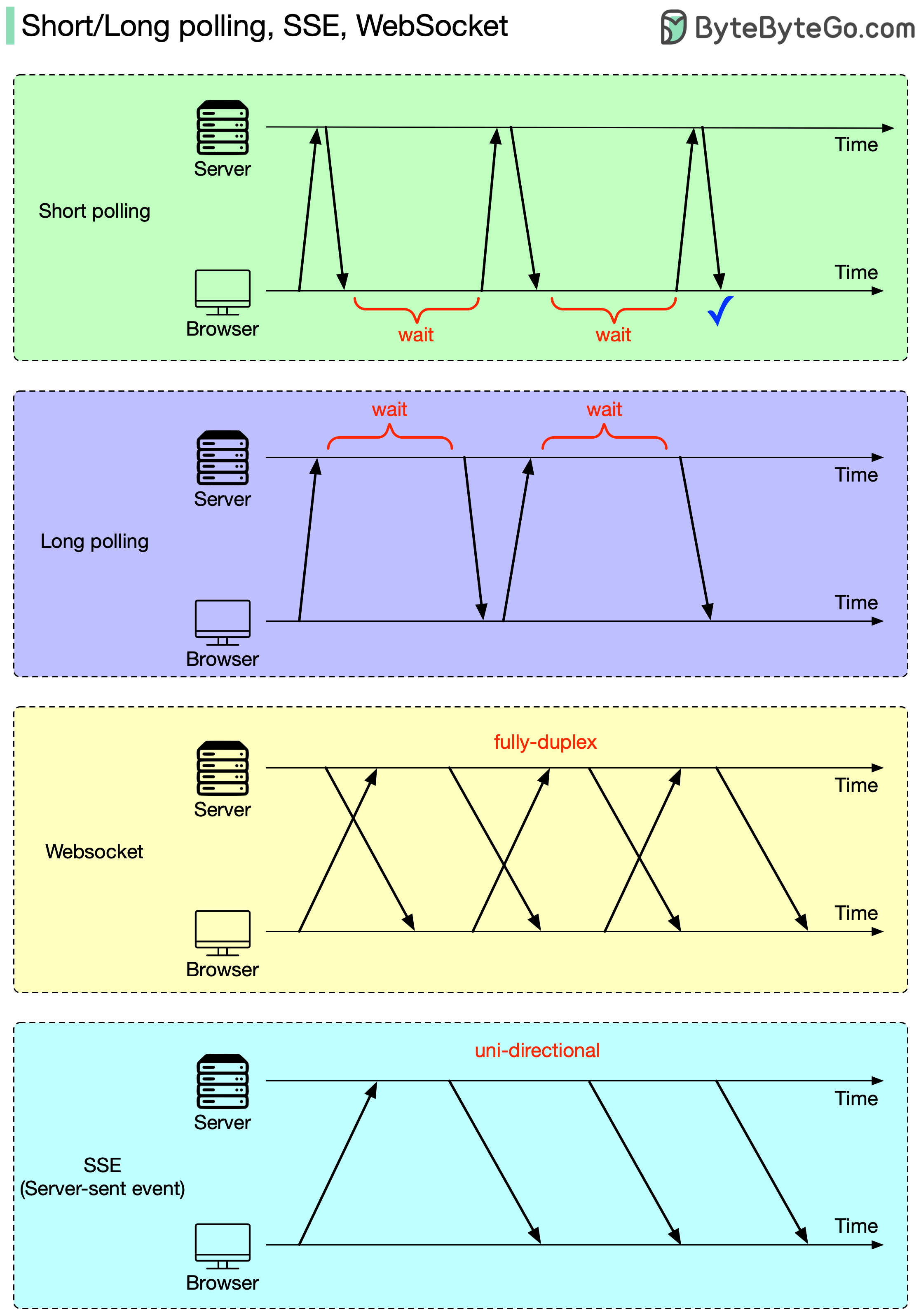
Here’s a simple visual of the process:
sequenceDiagram
participant Client
participant Server
Client->>Server: Start processing request
Server-->>Client: Job ID
loop Periodic Polls
Client->>Server: Poll with Job ID
alt Task Complete
Server-->>Client: Final Result
else Still Processing
Server-->>Client: Status Update
end
end

Under the hood, short polling interacts with fundamental system resources. Let’s highlight a few aspects for software engineers:
An analogy here is like a train station with tickets: each "job ID" is a small stub in memory pointing to the passenger’s journey. The kernel is the railway operator ensuring that trains (I/O events) are scheduled without collisions.
Where relevant, we can implement job tracking in Rust using an in-memory store like HashMap<JobId, JobStatus>. Below is a simplified snippet showing how job status might be tracked:
use std::collections::HashMap;
use std::sync::{Arc, Mutex};
use uuid::Uuid;
#[derive(Clone, Debug)]
enum JobStatus {
Pending,
InProgress(u8), // percentage
Completed(String), // final result
}
struct JobStore {
jobs: Mutex<HashMap<Uuid, JobStatus>>,
}
impl JobStore {
fn new() -> Self {
JobStore {
jobs: Mutex::new(HashMap::new()),
}
}
fn start_job(&self) -> Uuid {
let id = Uuid::new_v4();
self.jobs.lock().unwrap().insert(id, JobStatus::Pending);
id
}
fn update_job(&self, id: Uuid, status: JobStatus) {
self.jobs.lock().unwrap().insert(id, status);
}
fn get_status(&self, id: Uuid) -> Option<JobStatus> {
self.jobs.lock().unwrap().get(&id).cloned()
}
}
This approach lets clients poll by supplying a JobId, while the server updates the in-memory store. In production, distributed coordination (e.g., Redis, Kafka, or a database-backed store) would handle resilience and scale.
A good analogy here is checking a mailbox: short polling is like walking to your mailbox every 10 minutes. If the mail comes once a day, most trips are wasted. Event-driven protocols like WebSockets are akin to the postman ringing your doorbell when mail arrives.
On the other hand, when true real-time responsiveness matters—like chat applications or live dashboards—more advanced protocols are better suited.
Short polling is like a bridge between the simplicity of request-response and the sophistication of event-driven protocols. It gives us reliability and simplicity at the cost of some efficiency. As software engineers, understanding its memory implications, kernel-level involvement, and trade-offs helps us apply it wisely where it fits best.
If you’re building long-running services today, don’t dismiss short polling—it might be the pragmatic option that balances complexity, performance, and user experience.
If you want to discuss how we can apply these techniques in your project, feel free to contact us.
Would you like me to also create an SEO meta description and suggested keywords for this blog post?